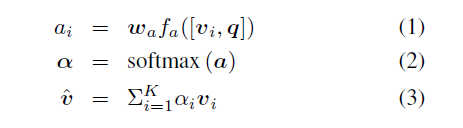BUTD注意力机制
在图像字幕和VQA中使用的大多数传统视觉注意机制都是自顶而下的,这些机制通常被训练成有选择地关注CNN的一个或多个层的输出,然而这种方法很少确定图像的关注区域

传统的CNN网络在引入注意力机制的时候,图像区域会分成大小均一的网格(左图),为了生成更像人类的字幕和问题答案,要将注意力自然地放在物体和其他突出的图像区域上,因此文章中提出的注意力机制是对象层面的(右图)
文章提出了一种结合自顶向下和自底向上的注意力机制,自底向上采用Faster R-CNN模型处理显著图像区域,每个区域由一个池化卷积特征向量表示,自顶向下采用task-specific来预测注意力区域,将其特征作为所有区域的图像特征的权重
相关工作
在VQA和图像字幕领域产生了大量基于注意力机制的深度神经网络,这些模型可以被归类为自顶向下的方法,注意力机制被应用于CNN的一个或多个层的输出。然而,确定图像区域的最佳数目总是需要在不同细节层次之间进行权衡,此外,与图像内容相关的区域的任意定位可能会导致检测到与区域不一致的物体,且将同一物体相关的视觉概念结合起来会变得更加困难
相对而来之前的研究很少考虑到将注意力集中到图像中的突出区域,注意到有这样两篇文献,[1]中使用选择性搜索来识别图像的显著区域,用分类器对显著区域进行过滤,然后对显著区域进行大小调整和CNN编码,并集合注意力输入到图像字幕模型中;注意力区域字幕模型[2]使用edge boxes或spatial transformer networks生成图像特征,使用基于三个双线性两两交互的注意力模型处理图像特征
[1] J. Jin, K. Fu, R. Cui, F. Sha, and C. Zhang. Aligning where to see and what to tell: image caption with regionbased attention and scene factorization. arXiv preprint arXiv:1506.06272, 2015.
[2] M. Pedersoli, T. Lucas, C. Schmid, and J. Verbeek. Areas of attention for image captioning. In ICCV, 2017.
文章工作
BottomUp Attention Model
在研究中,用bounding boxes来定义空间区域,用Faster R-CNN来实现自底向上注意力。Faster R-CNN是一个对象检测模型,用于识别属于特定类的对象实例,并使用边框对其进行定位
Faster R-CNN对对象的检测可以分为两个阶段,第一个阶段被称为区域候选网络(Region Proposal Network,RPN),用于预测目标区域,第二个阶段用region of interest (RoI)池化对每个候选区域提取一个小的feature map,这些feature map组合在一起,作为CNN最后一层的输入,最终输出一个基于类标签的softmax分布
文章中采用嵌入了ResNet-101的Faster R-CNN,原先的Faster R-CNN的多任务loss函数包含四个部分,文章中保留了这些部分,并添加一个额外的multi-class loss来训练属性预测器
以下是BottomUp模型输出的一个例子
Captioning Model
给定一组图像特征V,文章中提出的字幕模型使用一种自上而下的”软”注意机制,在字幕生成过程中使用现有的部分输出序列作为上下文,对每个特征添加权重
模型由两个LSTM构成
Top-Down Attention LSTM
输入:Language LSTM的上一步输出+平均池化后的BottomUp Attention Model输出的特征集+word embedding和one-hot编码的乘积
Language LSTM
输入:经过注意力处理的图像特征+Attention LSTM的上一步输出
最后输出为每个单词的概率,整个句子的概率是单个单词概率的连乘
模型要求最小化交叉熵损失
VQA Model
作者采用了tanh激活函数,用GRU提取问题特征,根据GRU的输出对图像特征生成非标准化注意力权重,然后计算标准化注意力权重和注意力图像特征
实验
SOTA比较
图像字幕
VQA
更多图像字幕的示例
成功的VQA示例
失败的VQA示例
![支付宝]() 支付宝
支付宝