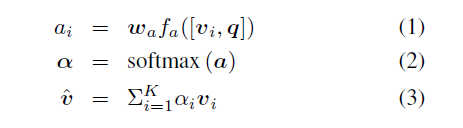Where To Look [注意力机制]
这篇文章主要致力于解决VQA和其它一些视觉推理问题中的一个核心任务:knowing where to look

如图所示,若红绿灯能够成功被定位,则可以轻易回答问题”What color is the walk light”,如何能够定位到雨伞,则有利于回答”Is it raining”,模型需要学习到被期待的答案的类型,以及做出回答需要基于图片的哪部分
where to look的实现是具有挑战性的,有些问答需要利用全图,而有些回答则需要关注特定的区域,文章中忽略需要额外知识辅助回答和需要推理回答的问题(比如图中男女在约会么)
作者的key idea是学习一个非线性映射,将图片和问题投射到相同的latent space来确定它们之间的关联,然后对相关区域和QA对的匹配度打分,latent space和打分函数由用QA对监督的margin-based loss来共同学习
文章主要的贡献为:
提出了一个图像区域选择机制,学习识别问题相关的图像区域
提出了一个采用margin-based loss的VQA多选题的学习框架,明显优于baseline
- 对baseline不使用图片,使用全图,使用加权的图像区域进行对比,对图像区域选择对VQA表现的影响提供了更细致的分析
Related Works
作者认为VQA可以被视为一种定向字幕任务,因此他参考了一些图片字幕task的paper,Fang et al在图像的不同部分检测到单词,并与语言模型结合在一起生成字幕,Xu et al采用RNN检测突出目标,逐个生成字幕词,而文章中的工作则是将问题文本作为输入来确定图像中的相关区域
文章中采用VQA数据集,因为多选题比开放问题更好评估,现在(2016)多数VQA数据集用图像标注来生成问题,这限制了所需的视觉和抽象知识的范围
作者称他们的模型受到End-to-End Memory Networks的启发,模型中的区域类似于该Paper中的句子,并类似地,学习了图片和问题的embedding到相同子空间,用内积来确定相关性
Ba et al采用了类似的框架,但是使用的是零样本学习方法,同样也是将语言和视觉特征投影到相同子空间中,采用内积进行相似性计算,但得分用于指导对象分类器的生成,而非图像区域排序
作者还提到了Bag-Of-Words,LSTM和word2vec,作者表示在实验中采用word2vec,发现挺好用的
Approach
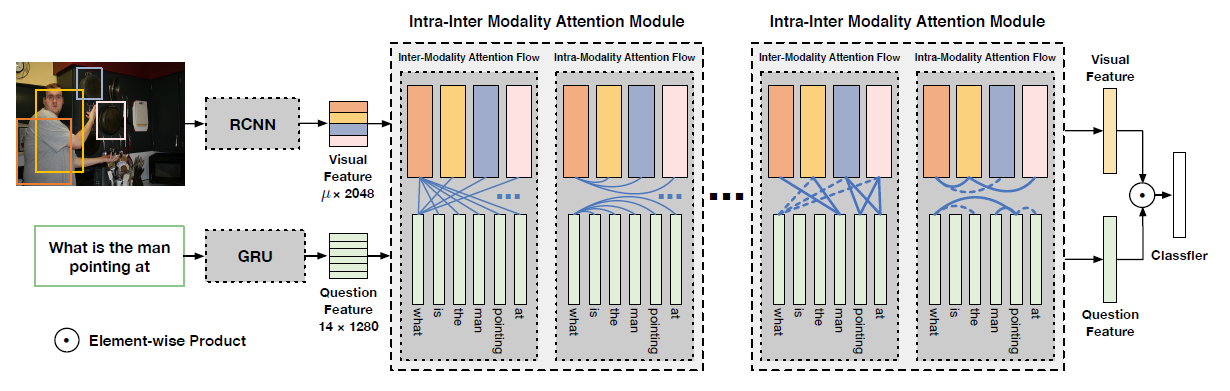
模型整体的框架如图,输入包含问题,潜在的答案,和一组自动选择的候选区域的图像特征,作者使用word2vec和一个两层的网络对解析后的问题和答案进行编码,每个区域图像特征用在ImageNet上预训练的CNN的前两层来编码,随后两个特征通过内积结合,然后用softmax去产生每个区域的权重,将加权平均值输入一个二层的网络得到区域的分数
QA Objective
作者希望最大化正确和错误选择之间的差距,作者通过以下loss函数实现这个目标
以上的目标要求正确答案$y_p$的分数至少比从一组错误答案中选出的最高分错误答案$y_n$的分数高一些
那么高多少呢,举个例子,6/10的标注着标注了答案p,而2/10个标注着标注了n,那么$y_p$得比$y_n$得分要高0.4
Region Selection Layer
模型的区域选择层有选择地结合输入的文本特征和来自图像相关区域的图像特征,为了确定相关性,该层首先将图片特征和文本特征映射到相同的一个N维空间,然后计算QA特征和每个图片区域特征的内积
设$G_r$是所有区域特征在$x_r$的列向量中的投影,gl是单个问答对词嵌入的投影,计算相关性权重的前馈传递计算方法如下
(4)式是内积之后做sofmax,b是偏移,内积的目的是迫使模型以类向量方式确定区域相关性
每个特征向量用W进行线性投影,利用$s_r$计算加权平均,得到每个问题和答案对的特征向量$a_l$,再通过relu层和批归一化层进行反馈
作者尝试过直接从连接的视觉和语言特征来预测关联分数,但是最终的模型与语言特征无关,内积是尝试过的唯一有效的方法
Language Representation
作者用300维的word2vec向量来表示单词,通过使用word2vec向量的平均值,为每一QA对构建固定长度的向量,然后学习如何对这些向量进行评分,实验表明这种向量表达方式明显优于更加复杂的基于lstm的模型
作者首先尝试对每个单词的问题和答案分别平均向量,并将它们连接起来得到一个600维的向量,但是由于word2vec表示不是稀疏的,平均单词可能会混淆表示
因此作者采用Stanford Parser来优化表示,将问题存储到额外的独立语义箱(bin)中,容器如下:
Bin 1:通过平均前两个单词的word2vec表示来捕获问题的类型(how many|is there|…)
Bin 2:编码问题的主语
Bin 3:包含所有其他名词词的平均值
Bin 4:包含所有剩余单词的平均值,不包括限定词如”a”、”the”和”few”
每个bin包含一个300维的表示,它与候选答案中的单词的bin连接在一起,生成一个1500维的问题/答案表示
下图展示了对解析后的问题封装的示例
Image Features
图像特征直接从预先训练好的网络输入到区域选择层,首先通过IOU为0.2的非最大抑制(NMS)提取排名最高的99个Edge Boxes,由于排名靠前的区域往往是高度重叠的大区域,这种具有侵略性的非最大抑制方法,对选取对某些问题有效的较小区域有十分重要的作用
最后,还添加了一个全图像区域,以确保模型在必要时至少具有全帧的空间支持,使得每张图像的候选区域总数达到100个
Experiments
消融实验
模型对比
可视化比较
L:Word only model
I:Word+Whole Image
R:Region Selection
![支付宝]() 支付宝
支付宝